Índice
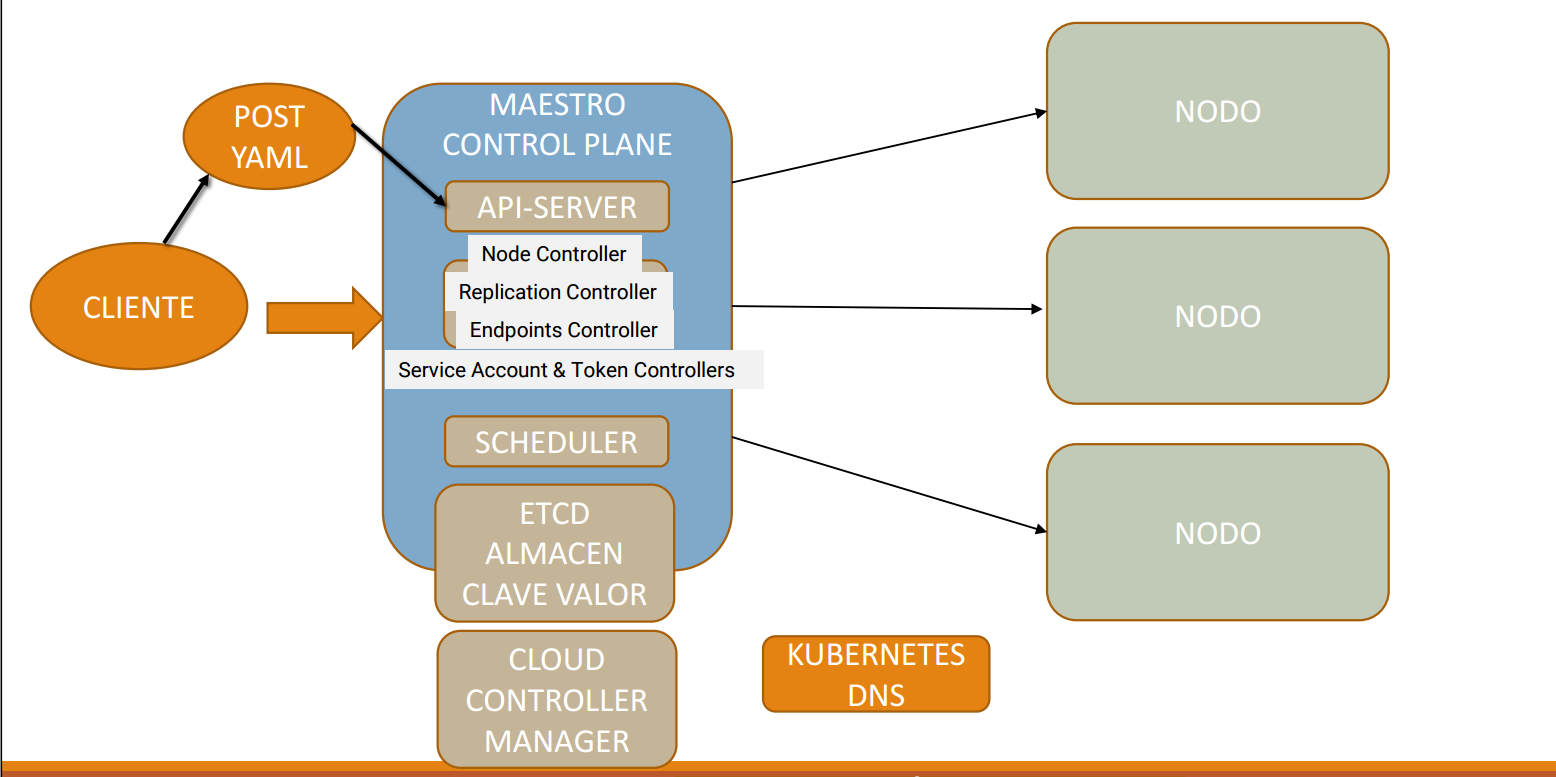
Arquitectura
Exploring the evolution from callbacks to async/await and beyond.
-
Cliente
Punto de inicio dónde tú o cualquier herramienta interactúa con el clúster.
Mediantekubectlo llamadas a la API. Manda peticiones al clúster como crear pods, servicios, deploys.
Normalmente se envían en archivos YAML que describen lo que quieres que K8s ejecute. -
POST YAML
Indica que el cliente envía el manifiesto YAML con una operación HTTP POST hacia el API Server.
Este YAML contiene las especificaciones que se quieren crear. -
MAESTRO / CONTROL PLANE
Cerebro del clúster:
- API Server: Puerta de entrada del clúster, recibe todas las peticiones, las valida, actualiza el
etcdy comunica la info a los demás componentes. - Controller Manager: Procesos que vigilan el estado del clúster y actúan para coincidir con el YAML.
- Node Controller: Vigila el estado y salud de los nodos.
- Replication Controller: Se asegura de que el número de réplicas (
pods) solicitados esté corriendo. - Endpoints Controller: Administra los endpoints que conectan servicios con pods.
- Service Account & Token Controllers: Gestionan las cuentas de servicio y tokens para autenticarse dentro del clúster.
- Scheduler: Decide qué nodo se va a ejecutar en cada pod evaluando recursos disponibles (
cpu,ram, afinidad, etc.). No los crea, solo asigna dónde van. - etcd: Almacén clave-valor, base de datos distribuida que guarda todo el estado del clúster (nodos, pods, secrets, configuraciones).
- Cloud Controller Manager: Permite que Kubernetes interactúe con recursos de la nube.
- API Server: Puerta de entrada del clúster, recibe todas las peticiones, las valida, actualiza el
-
Kubernetes DNS
Servicio interno que da nombres DNS a los servicios y pods, permitiendo comunicarte con ellos usando un nombre en lugar de una IP.
-
Nodos
Son las máquinas (físicas o virtuales) donde se ejecutan los pods y contenedores.
Cada nodo tiene su propiokubeletykube-proxypara comunicarse con el control plane.
-
Nodo
Como se mencionó antes, el nodo es una máquina física o virtual que forma parte del clúster donde se ejecutan realmente los Pods que Kubernetes orquesta.
-
Pods:
Unidad mínima desplegable en Kubernetes. Puede contener uno o varios contenedores que comparten red, almacenamiento y configuración, siguiendo lo definido en el YAML enviado. -
Container Runtime:
Software que ejecuta los contenedores en el pod. Kubernetes no ejecuta contenedores directamente, sino a través del runtime.
El más común es Docker, aunque también existen otros como containerd o CRI-O. -
Container Runtime Interface (CRI):
El Kubelet usa la CRI para comunicarse con el runtime, dándole instrucciones como “crear este contenedor” o “eliminar este contenedor”.
Gracias a la CRI, Kubernetes no depende de un runtime específico y puede usar múltiples opciones de forma intercambiable. -
Kubelet:
Agente que se ejecuta en cada nodo.
Recibe instrucciones del API Server (por ejemplo, crear un pod con cierta imagen), solicita al runtime que ejecute los contenedores necesarios, supervisa su estado y reporta continuamente al Control Plane.
Se asegura de que los pods definidos se estén ejecutando y funcionando correctamente. -
Kube-proxy:
Gestiona la red dentro de cada nodo.
Administra las reglas deiptablesoipvspara que los nodos puedan comunicarse entre sí y con el exterior.
Además, balancea el tráfico entre servicios.
Flujo resumido en el nodo
- El Kubelet recibe órdenes del API Server (por ejemplo, crear un pod con cierta imagen).
- El Kubelet usa la CRI para indicarle al Container Runtime que ejecute los contenedores.
- Los contenedores viven dentro de Pods.
- El Kube-proxy asegura que la red funcione para esos pods.
- El nodo reporta constantemente su estado al Control Plane.
Minikube
Se usa para ejecutar Kubernetes en local, pudiendo crear clústeres en una sola máquina física. No es recomendable usarlo en productivo.
Para crear clústeres con runtime Docker puedes usar estos comandos
minikube start -p dev --driver=docker
minikube start -p test --driver=docker
Si quieres listar los clústeres creados usa
minikube profile list
Para usar uno
minikube profile use test
Para detener un clúster
minikube stop -p dev
para reactivarlo
minikube start -p dev
para borrarlo
minikube delete -p dev
.kube/config
No es exclusivo de minikube, es un yaml con toda la configuración para que kubectl se comunique con el API Server. Permite definir multiples clusteres, usuarios y contextos para cambiar entre ellos facilmente.
Es como el archivo de credenciales y rutas que le dice a kubectl: “Conéctate a este clúster, con este usuario, usando este certificado, y en este namespace por defecto”.
clusters
Incluye:
- Nombre del clúster
- Dirección del API Server
- Certificado del clúster para conexiones seguras
clusters:
- cluster:
certificate-authority: /home/usuario/.kube/ca.crt
server: https://192.168.99.100:8443
name: mi-cluster
users
Credenciales de acceso(usuarios o service accounts), puede usar:
-
Tokens
-
Certificados cliente
-
Usuario/contraseña
-
Integraciones con nubes (ej: EKS, GKE, AKS)
users:
- name: mi-usuario
user:
client-certificate: /home/usuario/.kube/client.crt
client-key: /home/usuario/.kube/client.key
context
Es la combinación de
- Un clúster
- Un usuario
- (Opcional) Un namespace por defecto
Permite tener varios entornos configurados (ej: desarrollo, pruebas, producción) y cambiar entre ellos fácilmente.
contexts:
- context:
cluster: mi-cluster
user: mi-usuario
namespace: dev
name: dev-context
current-context
Indica cual contexto definido se está usando por defecto
current-context: dev-context
Funciona asi, tu ejecutas una operación y
- Lee el
current-context. - Usa el cluster y user definidos en ese contexto.
- Se conecta al API Server con esas credenciales.
- Aplica la operación (ej: listar pods).
Comandos relevantes
kubectl config view
kubectl config current-context
kubectl config use-context prod-context
kubectl config get-contexts
Namespaces
Un namespace en Kubernetes es como una carpeta virtual dentro del clúster que te ayuda a organizar, aislar y controlar recursos (pods, servicios, deployments, etc).
Dos objetos con el mismo nombre pueden existir en el cluster siempre que estén en namespaces distintos.
Un uso común de los namespaces es dividirlos en dev, test y prod. Dentro de dev puedes tener un service llamado backend, mientras que en prod puedes tener tambien el service backend. Además puedes dar permisos a ciertos usuarios para trabajar solo en un namespace. Ademas puedes limitar el uso de recursos (cpu, memoria) de cada namespace.
Comandos útiles
kubectl create namespace dev
kubectl get namespaces
kubectl delete namespace dev
#ver recursos de un namespace especifico
kubectl get pods -n dev
Ciclo de vida
El imperativo es con un comando y no se recomienda en producción o casos robustos, pues el declarativo es quien puede levantar la aplicación con un estado deseado
PODS
La aplicación es una imagen almacenada en algun repo, esta se despliega declarativamente mediante un yaml en un pod. El pod podría contener varios contenedores, pero esto no se recomienda ya que si algo le pasa a dicho pod, se caería el resto de servicios. Por ejemplo si actualizas el mysql, los demas servicios se apagarian tambien o el mero hecho de compartir ip ya lo vuelve absurdo.
Estar empaquetado en esa burbuja del pod, le da caracteristicas a dicho contenedor englobandolo en una IP
PODS IMPERATIVO
Con estos comandos se puede crear un pod y despues obtener sus datos básicos
kubectl run nginx1 --image=nginx
kubectl get pods -o wide
puedes usar describe para obtener más info del pod. No olvides que antes del id se usa ‘pod/’
kubectl describe pod/nginx1
Tambien puedes acceder a la terminal de un contenedor
kubectl exec nginx1 -- ls
kubectl exec nginx1 -it -- bash
tambien puedes hacer ciertas especificaciones al crear un pod, como elegir el puerto
kubectl run apache --image=httpd --port=8080
Para obtener los logs observando cambios en tiempo real se usa
kubectl logs -f apache
Puedes borrar un pod con
kubectl delete pod nginx
kubectl delete pod apache --grace-period=5
Con el proxy puedes acceder a un listado de direcciones dentro de kubernetes, donde puedes obtener una descriupción detallada de caracteristicas
kubectl proxy
http://localhost:8001/api/v1/namespaces/default/pods/apache/proxy/
Introducción a YAML
#Las cadenas no requieren comillas:
Título: Introducción a YAML
# Pero se pueden usar:
title-w-quotes: 'Introducción a YAML'
# Las cadenas multilínea comienzan con |
ejecutar: |
npm ci
npm build
prueba npm
#Secuencias
#Las secuencias nos permiten definir listas en YAML:
# Una lista de números usando guiones:
números:
- uno
- dos
- Tres
# La versión en línea:
números: [uno, dos, tres]
#Valores anidados
#Podemos usar todos los tipos anteriores para crear un objeto con valores anidados, así:
# Mil novecientos ochenta y cuatro datos nuevos.
1984:
autor: George Orwell
publicado en: 1949-06-08
recuento de páginas: 328
descripción: |
Una novela, a menudo publicada como 1984, es una novela distópica del novelista inglés George Orwell.
Fue publicado en junio de 1949 por Secker & Warburg como noveno y último b de Orwell.
#Lista de objetos
#Combinando secuencias y valores anidados podemos crear una lista de objetos.
# Hagamos una lista de libros:
- 1984:
autor: George Orwell
publicado en: 1949-06-08
recuento de páginas: 328
descripción: |
Una novela, a menudo publicada como 1984, es una novela distópica del novelista inglés George Orwell.
- el Hobbit:
autor: J. R. R. Tolkien
publicado en: 1937-09-21
recuento de páginas: 310
descripción: |
The Hobbit, o There and Back Again es una novela de fantasía para niños del autor inglés J. R. R.
PODS DECLARATIVOS
Aqui se sigue el ciclo de vida. Primero se crea una imagen docker para despues desplegarla a un pod mediante el YAML.
Primero se verifica que estas logeado a tu registry
docker login
Para crear la imagen usamos el dockerfile y despues lo subimos al registry
docker build -t mazaalain/nginx:v1 .
docker push mazaalain/nginx:v1
Finalmente contando con el yaml que declara las caracteristicas, se puede crear con
kubectl create -f nginx.yaml
En el yaml es bastante importante la etiqueta kind, ya que determina que es lo que estás levantando. en este ejemplo fue un pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
zone: prod
version: v1
spec:
containers:
- name: nginx
image: mazaalain/nginx:v1
puedes obtener detalles de un pod en formato yaml o json con estos comandos
kubectl get pod/nginx -o json
kubectl get pod/nginx -o yaml
El comando create, como se mencionó, permite levantar el pod, sin embargo si se requiere modificar, se tendría que eliminar y luego volver a hacer un create. Es por ello que se usa el comando apply, pues es quien realmente permite una gestión declarativa de kubernetes, ya que si no existe el recurso lo crea, pero si existe, lo modifica, sin necesidad de cambiar configuraciones como la ip, osea mantiene su estado.
kubectl apply -f nginx.yaml
RestartPolicy
Los contenedores tienen una propiedad llamada restartPolicy que dictamina las políticas de reinicio de pods. Existen tres tipos
- Allways - Siempre reinicia el pod, sin importar si fue fallo o detención manual (viene por defecto)
- OnFailure - Reinicia solo si falla
- Never - nunca reinicia
Además al describir un pod, verás que pese a seguir activo, aumenta en 1 en restart
En el caso de OnFailure este seguiría reiniciandose hasta que tenga una salud optima y never pues se mantendria con 0 restarts
Labels y Selectors
Para mostrar las labels se usan estos comandos. Si pones una etiqueta en -L que no exista, se podrá vacio su valor
kubectl get pod tomcat --show-labels -L apps
kubectl get pod tomcat --show-labels
Para agregar una label se usa
kubectl label pod tomcat responsable=juan
Para modificar una label se usa
kubectl label --overwrite pod/tomcat responsable=miguel
para eliminar una label se usa
kubectl label pod/tomcat responsable-
Pese a estos comandos, lo mejor es ponerlos de forma declarativa en el yaml
Puedes tambien usar los selectores, para hacer busquedas entre las etiquetas. Estos van con la -l
kubectl get pods --show-labels -l estado=test,responsable=juan
kubectl get pods --show-labels -l estado=test,responsable!=juan
se pueden usar conjuntos para busquedas mas potentes
kubectl get pods --show-labels -l 'responsable in (juan, pepe)'
kubectl get pods --show-labels -l 'responsable notin (juan, pepe)'
los selectores no solo sirven con get pods, funcionan con cualquier comando
kubectl delete pods -l responsable=pepe
las anotations sirven para poenr descripciones o documentacion en el yaml de forma declarativa
DEPLOYMENTS
WORKLOADS Y CONTROLLERS
Los workloads son cargas de trabajo que defines en k8s, puededn ser apps, jobs, deamons etc mdiante archivos YAML nviados al API Server
K8s nunca gestiona pods sueltos, si no que gestiona mediante Controllers
Los controllers son los objetos que gestionan los pods para asegurar el estado deseado y cada uno tiene un rol especifico. En la magen vemos los tipos de controllers que son los deployments, ReplicaSet, StatefulSet, DaemonSet, job y conjobs
Esta seccion compete a Deployments
Introducción a deployments
Un pod por si mismo no puede escalarse, recuperarse ante caidas ni realizar updates y rollbacks complejos. Es por eso que existen los deployments, los cuales realizan todas estas operacion que los pods no puedden. Ademas se crea por defecto un replicaset.
El deployment gestiona dicho replicaset, gestionando rolling updates,rollbacks y versiones. Sin embargo el replicaset es el controller que garantiza el numero de pods corriendo. Es por ello que no suele usarse un replicaset directamente, si no mediante un deployment que lo gobierne.
Deployments imperativos
Se usa el comando siguiente, donde “apache” es el nombre del deployment
kubectl deployment apache --imahe=http
estoc rea deployment, replicaset y pods
Para ver los deploys usa
kubectl get deploy
Ready significa que existe y available que esta funcionando
Para listar los replicaset se usa
kubectl get rs
tienen le mismo nombre del deployment pro con unos numeros despues (apache-837493)
En cuanto a los pods se usa el mismo comando que hemos usado, pero tiene la nomclatura del replicaset seguido de otros numeros (apache-837493-nd88k)
kubctl get pods
Para ver mas info de los deployments puedes usar
kubectl describe apache
kubectl describe apache -o yaml
Deployments declarativos
para levantar tu deployment tienes que tener tu trminal ubicada en el archivo y usar el comando
kubectl apply -f deploy_nginx.yaml
si quieres editar tu deployment, debes modificar tu yaml y volver a aplicar un apply
Tambien puedes usar el comando edit, el cual es mas dinámico pues te abre directo el yaml
kubectl edit deploy nginx-d
Puedes escalar directamente un deploy con
kubectl scale deploy nginx-d --replicas=4
Tanto scale como edit modifican directamente el estado del cluster (en etcd) pero no modifican el yaml original asi que rompe un poco con la idea gitOps 100&dclarativo. Lo ideal siempre será usar el apply
En cuanto a replicas y escalado de bases de datos, no aplica la msima logica. Considera usar recursos como mysql cluster o mysql galera. Asi el software ded esa sosluciones se encargan d las replicas, no lo hace kubernetes.
Services
Si tienes un deployment con 4 pods ¿Como se conectaria al cliente, si su ip fija no la conoces y si se cae cambia? Como no se puede conectar de manera directa, exiaste un componente intermedio que conecta clietnes con deployments. Estos son los servicios. Tienen una ip, nombre y puerto fijos.
Existen 3 tipos principales
- ClusterIP - para uso interno del cluster como bases de datos, servidores intermedios y todo el backedn que no es expusto al cliente
- NodePort - si es accesible al cliente, osea deasde el exterior
- LoadBalancer - Accesible igual desde fuera pero se integra a loadbalancers externos, pero se comporta igual que el nodeport
Los servicios funcionan mediante sleectors y labels
Servicios imperativos
Se crean con el comando
kubectl expose deploy apache1 --port=80 --type=NodePort
por debecto pone el cluisterIP si no pones un type
Para ver los services usa, aqui verás el puerto que te asigno al servicio, recuerda que el port que asignas en el comando se arriba es el puerto al que responde tu deploy. El valor por el que se accede desde afuera es el nodedPort
kubectl get svc
o si quieres ver la url completa en minikube usa
minikube service list
para ver mas detalles del servicio usa este comando y la seccion llamada Endpoints significan los pods que se le asignaron
kubectl describe svc apache1
Para escalar un service usa
kubectl scale deploy apache1 --replicas=3
Si un pod muere, este se regenera acuerdo al state y el servicio automaticamente lo integra.
Lo unico diferente de un loadBalancer y nodePort es que el primero expone una externalIP la cual permite su integración a un servicio cloud
Respecto a los cluster IP que solo estan disponibles internamente, para conectarte a uno puedes usar el nombre del servicio, pero siempre internamente de un servicio en el cluster y usando por ejemplo este comando de host. En este ejemplo entras al master, mediante el cli.
redis-cli -h redis-master
Servicios de forma declarativa
Se puede crear el deployment y servicio en un solo archivo si usas los - - -
y para levantarlo se usa el apply
kubectl apply -f completo.yaml
Recuerda que en un describe de un servcie los Endpoints son los pods asignados y son un kind especifico
Por lo que puedes obtener mas ingo con estos comandos
kubectl get endpoints
kubectl get endpoints web-svc -o wide
kubectl describe endpoint web-svc
Recuerda que un servicio crea un conjkunto de variables de entorno en los pods del deployments asignado
Conexión Deployment - Service
La clave entre su conexión está en las labels y selectors.
Un Deployment, normalmente pones labels en sus Pods
Este Deployment creará Pods con la etiqueta app=mi-app.
Luego un Service usa un selector para decir “Quiero enviar tráfico a los pods que tengan app=mi-app"
Así el service detecta automaticamente los pods creados por el deployment que tiene la misma label
Si existen multiples labels, todas tienen que coincidir ya que la relación siempre es de un AND lógico
Port vs NodePort vs TargetPort vs ContainerPort
El yaml de un service puede verse asi
targetPort y containerPort
Es el puerto dentro del contenedor (pod), por ejemplo si es un nginx, escucha en 8080. Este se define en el deployment mediante containerPort a manera de anotación y sin abrir, diciendo que el contenedor escucha en ese puerto. Repito, kubernetes no usa contianerPort para rutear tráfico. Es en el service donde se usa targetPort donde se abre dicho puerto para dirigir el tráfico. Podrías NO DEFINIR containerPort en tu deployment y aun asi funcionaria al usar el targetPort
targetPort = puerto del contenedor.
port
Es el puerto que el service expone dentro del cluster. Funge como un puerto lógico que es accesible por DNS (mi-app-service.default.svc.cluster.local:80) es el puerto que usarán otros pods DENTRO del cluster para conectarse. ES INERNO DEL CLUSTER
port = puerto interno del Service dentro del clúster.
nodePort
Solo existe cuando type: NodePort Es un puerto en el nodo físico/virtual que se abre para dirigir tráfico hacia el service, permitiendo acceder DESDE FUERA del cluster, usando la ip del nodo. No es obligatorio definirlo, ya que kubernetes asignará uno entre 30000-32767.
nodePort = Es el puerto de acceso externo al nodo.
Respecto a la IP, el Service sigue teniendo su ClusterIP (ej: 10.96.0.12:80), accesible solo dentro del clúster. Pero además expone un puerto en los nodos (nodePort, ej: 30080). Así puedes acceder desde fuera con la IP de cualquier nodo:
http://<NodeIP>:30080
Kubernetes se encarga de redirigir ese tráfico al Service y luego al Pod correcto.
Caso LoadBalancer
Funciona como NodePort pero además pide al cloud provider (AWS, GCP, Azure, etc.) que cree un load balancer externo. Este LB apunta a los nodePort que Kubernetes abrió.
Por eso no ves nodePort en el YAML del LoadBalancer:
- Se asigna internamente.
- Normalmente no necesitas preocuparte porque accedes al LB con la IP/DNS pública que te da el proveedor.
Respecto a la IP, Suma lo anterior (ClusterIP y NodePort), pero además pide al cloud provider un Load Balancer público. Ese LB recibe una IP/DNS pública y redirige tráfico hacia los NodePorts.
http://34.120.45.67:80 # IP pública del LoadBalancer
O sea existe una ip pública del loadbalancer que dirige despues a los nodePorts de tu cluster. Y asi el flujo.
Caso clusterIP
Al ser exclusivamente interno, solo expone el port dentro del cluster y no tiene un nodePort. En otras palabras, solo otros pods internos van a poder acceder a el.
Cada Service de tipo ClusterIP recibe una IP interna del clúster (ejemplo: 10.96.0.12) Esa IP solo es accesible desde dentro del clúster. Ejemplo como accedería otro pod
http://10.96.0.12:80
Sin embargo, normalmente no se usa la IP sino el DNS automático
http://<service_name>.<namespace>.svc.cluster.local:80
Namespaces
Es un espacio que organiza y divide los recursos de k8s. Puedes listar los namespaces con
kubectl get namespace
Hay namespaces especificos de k8s que son autogestionados por la herramienta en si
Para crear un namespace necesitas un yaml como este
apiVersion: v1
kind: Namespace
metadata:
name: dev1
labels:
tipo: desarrollo
y aplicas el comando
kubectl apply -f namespace.yaml
Puedes obtener mas info de un namespace con
kubectl describe namespace
Para crear un deployment sobre un namespace, aplicas el deploy normal pero con el parametro —namespace=
kubectl apply -f deploy_elastic.yaml --namespace=dev1
puedes usar la apbreviatura -n
kubectl get deploy elastic -n dev1
kubectl describe deploy elastic -n dev1
Si no agregas el -n especificando el namespace en que se encuentra, k8s lo buscara en default y por ende, saldrán errores pues dichos recursos no existen en el namespace default
Si requieres cambiar el namespace por defecto, con el comando siguiente puedes ver la configuracion de kube, donde en context aparecera el namespace configurado en tu cluster
kubectl config view
asi que para establecer un nuevo namespace por defecto, puedes usar este comando
kubectl config set-context --current -n-namespace=dev1
Se pueden limitar los recursos a un namespace, como ya vimos con un describe se opbservan los recursos asignados
aplicando en un yaml ciertas configuraciones se logra cambiar esto
apiVersion: v1
kind: LimitRange
metadata:
name: recursos
spec:
limits:
- default:
memory: 512Mi
cpu: 1
defaultRequest:
memory: 256Mi
cpu: 0.5
max:
memory: 1Gi
cpu: 4
min:
memory: 128Mi
cpu: 0.5
type: Container
kubectl apply -f limitex.yaml -n dev1
y ahora aparecen los neuvos limites
Pueds obtener los eventos que se han generado en un namespace con
kubectl get events --namespace dev
kubectl get events --field-selector reason='Scheduled' --namespace dev
y asi observar todo lo que se a ido realizando en un namespace
Variables
Las variables estan en al sección env. Las variables funcionan igual que en docker, tu las defines en el yaml y despues estan disponibles en tu entorno docker accediento a el y usandolas libremente $var
puedes ver las variables en linux con
printenv
ConfigMaps
Cuando se tienen muchas variables, entran los configmaps, ficheros que incorporan un conjunto de propiedades clave-valor para ponerlos a disposición a modo de envs en los pods. Su proposito es separar la configuración de la aplicación de la imagen del contendor para no tener que reconstruir la imagne cada vez que cambias un valor ded su condiguración. Cabe recalcar que son usados para información no sensible.
Se peuden crear de este modo
kubectl create configmap cf1 --from-literal=usuario=usu1 --from-literal=password=pass1
Y obtener información con
kubectl describe cm cf1
Tambien se puede cargar con ficheros apra no hacer comandos tan largos
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
MYSQL_DATABASE: appdb
MYSQL_USER: appuser
kubectl apply -f mysql-configmap.yaml
kubectl describe configmap mysql-config
y en l deployment se aplicaria de esta forma
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
envFrom:
- configMapRef:
name: mysql-config # Importa todas las variables del ConfigMap
env:
- name: MYSQL_ROOT_PASSWORD
value: rootpass123 # En la práctica esto va en un Secret
ports:
- containerPort: 3306
y la manera de verificar su implementación sería con
kubectl apply -f mysql-deployment.yaml
kubectl get deployments
kubectl get pods -l app=mysql
kubectl exec -it <nombre-del-pod> -- bash
env | grep MYSQL
En el describe te das cuenta que fue aplicado correctamente por que se ve asi
Secrets
Es similar a los secrets, pero con la peculiaridad de que al ser usados para información confidencial, se lamacenan en Base65 dentro de etcd. Suele ser usado para almacenar contraseñas de bd, tokens de apis, certificados ssl/tls o llave sprivadas.
La manera ams optima de trabajarlos, es declarativamente aunque puede ser tambien mediante comandos de una linea como los configmaps. Declarativamente, ussando el YAML, los valores deben ingresarse ya en base64 si se usa el ‘data’ hay una manera de ingresarlos como string para que k8s lo codifique, pero lo mejor será siempre ponerlos ya codificados.
apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
type: Opaque
data:
MYSQL_ROOT_PASSWORD: cm9vdHBhc3MxMjM= # "rootpass123" en Base64
echo -n "rootpass123" | base64 #para codificar la cadena a base64
kubectl apply -f mysql-secret.yaml
como siempre, se obtiene info de los secrets con
kubectl describe secret mysql-secret
o si ya quieres ver el valor real se usa
kubectl get secret mysql-secret -o yaml
echo "cm9vdHBhc3MxMjM=" | base64 --decode #para decodificar lo que muestre el comando anterior
finalmente en el deployment se usaria de esta forma
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
envFrom:
- configMapRef:
name: mysql-config # Configuración no sensible
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: MYSQL_ROOT_PASSWORD
ports:
- containerPort: 3306
Los secrets no encriptan, solo codifican, por ello siendo inyectados al contenedor, dentro de el ya s epuede apreciar como la cadena con el valor real. Estando ya en el contenedor, el secret es tan seguro como el contenedor mismo, por eso hay que tener buena protección en los permisos de acceso.